https://github.com/dorae222/HAI_Kaggle_Competition
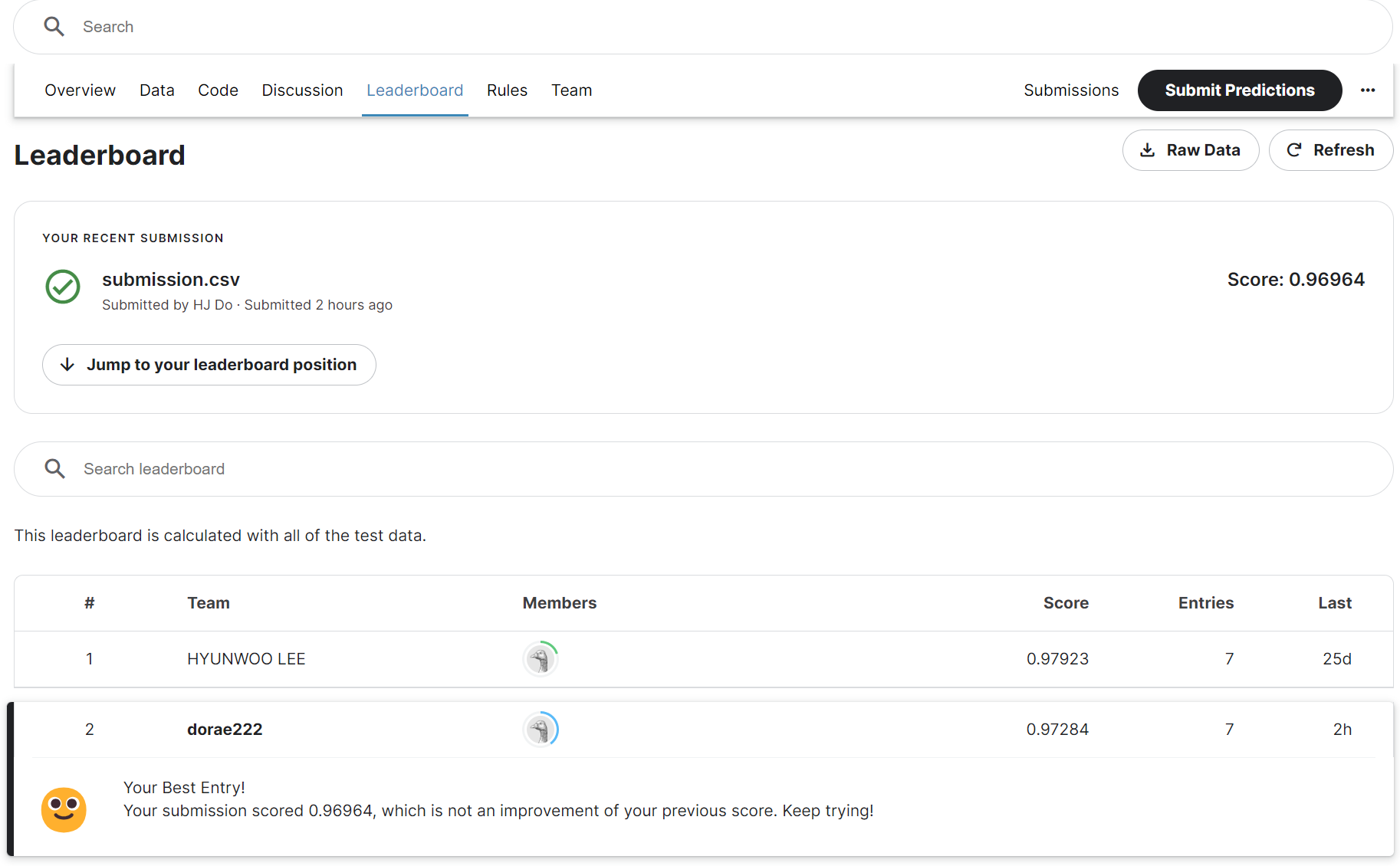
캐글에서 타이타닉 데이터셋 제출을 해본 것을 제외하고, 직접 Commit 해보는 것은 처음이었습니다.
현재 기준으로 97.2%정도의 정확도로 2등에 위치해 있습니다.
실험을 진행하며 이번 대회에서 성능을 높이기 위한 포인트를 몇가지 남겨보고자 합니다.
(자세한 코드가 궁금하다면 아래 링크에서 확인 가능합니다.)
1. 왜 GPT 계열이 아닌 BERT 계열을 선택해야 하는가?
(이 부분과 관련하여 이전 글 제일 아래 부분에서 간략하게 다루었습니다.)
머신러닝 기법들도 적용을 했을 때, 전처리에 심혈을 기울였음에도
성능이 80% 이상 나오지 않아 BERT 계열의 모델을 최종적으로 선택하였습니다.
2. 데이터셋의 분포를 고려해야 한다.